Mac OS Mavericks下安装单机版Hadoop
以下记录了我在Mac OS Mavericks下安装单机版Hadoop的经历。中间遇见了好多在Linux上没有遇到过的错误,尤其是因为主机名(HostName)等网络设置导致各种错误,真是太考验耐心了,不过,最后总算是跑起来了~~
一、计算机配置如下
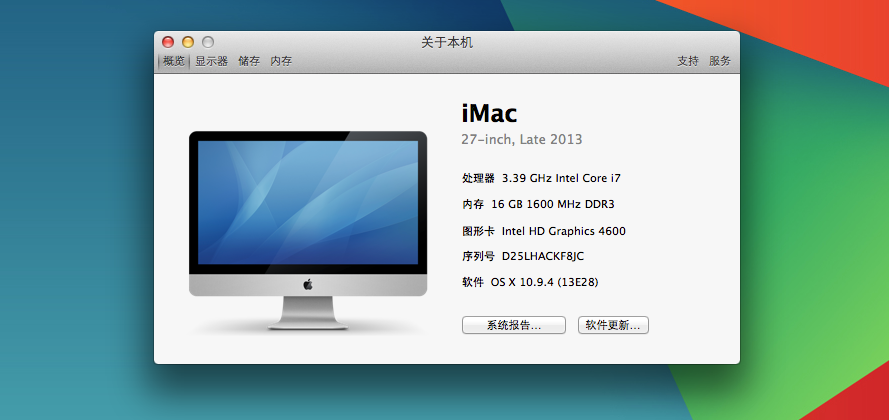
二、软件版本
1.Java版本,使用OS系统自带的就可以
java version "1.6.0_65"
Java(TM) SE Runtime Environment (build 1.6.0_65-b14-462-11M4609)
Java HotSpot(TM) 64-Bit Server VM (build 20.65-b04-462, mixed mode)2.SSH版本,使用系统自带的就可以
OpenSSH_6.2p2, OSSLShim 0.9.8r 8 Dec 2011
Bad escape character 'rsion'.3.Hadoop版本
hadoop.1.0.3.tar.gz三、安装过程
1.安装Java
看过很多教程,都推荐用Java 1.6版本,系统自带的就可以,使用以下命令查看Java版本
$java -version2.安装SSH
Mac OS X自带了Open-SSH不用再手动安装。接下来设置SSH免密码登录。
- 使用以下命令生成RSA私钥和公钥(如果已经生成过的,请跳过)
$ssh-keygen -t rsa -P "" –f $HOME/.ssh/id_rsa- 将公钥内容添加到authorized_keys列表里(如果已经添加过的,请跳过)
$cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys- 测试登录
$ssh localhost
$ssh USERNAME@HOST_NAMEps:USERNAME表示用户名,HOST_NAME表示主机名
3.设置主机名和计算机名称
Mac OS X的主机名称分为本地主机机名和网络主机名,这个要搞清楚,在后面设置Job tracker时要用到,很重要。
建议把计算机名也设置成和主机名一样的。
建议主机名全部使用小写字母,不要使用特殊字符,包括-也不要使用。
可以使用下面的命令设置
$sudo scutil --set ComputerName newname
$sudo scutil --set HostName newname计算机名(Computer Name)和主机名(Host Name)设置完成后可以在共享设置页面查看到,终端的$前的名字是计算机名(Computer Name)。
ps: 以下是我的计算机信息
- 用户名:liang
- 计算机名:liangsimac
- 本地主机名:liangsimac.local
- 网络主机名:liangsimac
4.准备Hadoop安装包
建议下载源码包,里面包含了默认的配置文件,请访问下面的链接下载hadoop-1.0.3.tar.gz
https://archive.apache.org/dist/hadoop/core/hadoop-1.0.3/将hadoop-1.0.3.tar.gz解压到以下目录
/usr/local/share/hadoop-1.0.35.设置环境变量
修改/etc/bashrc文件,添加以下配置
# define HADOOP_HOME
export HADOOP_HOME="/usr/local/share/hadoop-1.0.3"
export HADOOP_PREFIX=${HADOOP_HOME}
export HADOOP_BIN_HOME="$HADOOP_HOME/bin"
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_CONF_DIR="$HADOOP_HOME/conf"
export HADOOP_PID_DIR="$HADOOP_HOME/run/hadoop-pid"
export PATH=${PATH}:${HADOOP_BIN_HOME}:${HADOOP_CONF_DIR}执行以下命令,使得配置生效
$source /etc/bashrc6.修改hosts文件
通过ifconfig命令查到本机ip,比如我的ip地址为10.237.250.47,然后添加如下信息
10.237.250.47 liangsimac.local liangsimac然后可以ping liangsimac,确保已经生效。
7.配置Hadoop
有6个文件需要修改,分别是
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
masters
slaveshadoop-env.sh
这个文件包含运行Hadoop需要的环境变量,请添加以下代码来解决可能出现的一个启动时打印日志异常
export HADOOP_OPTS="-Djava.security.krb5.realm=-Djava.security.krb5.kdc="core-site.xml
这个文件是Hadoop的一些核心配置,比如I/O设置等。
首先要将hadoop包目录下src/core/core-default.xml拷贝到conf/目录下,重命名为core-site.xml。找到如下的字段并修改:
<property>
<name>fs.default.name</name>
<value>hdfs://liangsimac:9000</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/Users/liang/Hadoop/tmp/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description>
</property>其中:
1.fs.default.name字段应该是Master节点主机名(MASTER_HOST_NAME),比如,我的主机名为liangsimac。
2.hadoop.tmp.dir字段是存放Hadoop运行中的一些临时文件的目录。
hdfs-site.xml
这个文件控制了Hadoop分布式文件系统处理,name-node,secondary name-node,data-nodes等相关的配置。
首先要将hadoop包目录下src/hdfs/hdfs-default.xml拷贝到conf/目录下,重命名为hdfs-site.xml。找到如下的字段并修改:
<property>
<name>dfs.replication</name>
<value>1</value>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
</description>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off,
but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode,
owner or group of files or directories.
</description>
</property>其中:
1.dfs.replication字段是缺省的块复制数量。如果我们想利用所有节点的所有计算力量,这个值应该等于可利用节点数。
2.dfs.permissions字段是文件操作时的权限检查标识。
mapred-site.xml
这个文件控制着MapReduct process, the job tracker, the tasktrackers的相关配置。
首先要将hadoop包目录下src/mapred/mapred-default.xml拷贝到conf/目录下,重命名为hdfs-site.xml。找到如下的字段名修改:
<property>
<name>mapred.job.tracker</name>
<value>liangsimac:9001</value>
<description>The host and port that the MapReduce job tracker runs
at. If "local", then jobs are run in-process as a single map
and reduce task.
</description>
</property>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>1</value>
<description>The maximum number of map tasks that will be run
simultaneously by a task tracker.
</description>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>1</value>
<description>The maximum number of reduce tasks that will be run
simultaneously by a task tracker.
</description>
</property>
<property>
<name>mapred.max.split.size</name>
<value>1000</value>
</property>其中:
1.mapred.job.tracker字段是job-tracker交互端口,必须指向master节点和正确的端口,Hadoop集群中只有master节点运行着job tracker,该字段应该设置为MASTER_HOST_NAME:port。
2.mapred.tasktracker.map.tasks.maximum字段表示task管理器可同时运行map任务的数量。
3.mapred.tasktracker.reduce.tasks.maximum字段表示task管理器可同时运行reduce任务的数量。
4.mapred.max.split.size字段关系着Hadoop如何通过HDFS分割(splits)和分发(distributes)输入文件。
masters
请将下面的字段写入masters文件中
MASTER_USERNAME@MASTER_HOST_NAME比如,我的masters文件为:
liang@liangsimacslaves
请将下面的字段写入slaves文件中
MASTER_USERNAME@MASTER_HOST_NAME
SLAVE_USERNAME_1@SLAVE_HOST_NAME_1
SLAVE_USERNAME_2@SLAVE_HOST_NAME_2
SLAVE_USERNAME_3@SLAVE_HOST_NAME_3比如,我的slaves文件为:
liang@liangsimac8.启动Hadoop
1.格式化HDFS文件系统
请执行一下代码来格式化namenode
hadoop namenode -format2.运行Hadoop
因为之前已经将$HADOOP_HOME/bin添加到系统环境变量了,所以,可以直接执行下面的命令来启动Hadoop
start-all.sh3.通过jps命令检查运行状况如下,表示所有的服务都开启了
36783 TaskTracker
38771 Jps
36647 SecondaryNameNode
19283
36703 JobTracker
36565 DataNode
36483 NameNode4.访问下面两个页面表示服务正常运行
http://localhost:50030
http://localhsot:50070其中:
- 50030: 表示Hadoop Map/Reduce任务运行进度监控信息
- 50070: 表示Hadoop NameNode的运行信息